
Smoothie Scan
Background
I received a wonderful gift recently- a magazine full of smoothie recipes! Anyone who knows me knows that I have a smoothie with breakfast basically every morning of my life. I didn’t realize until I received this gift, but I really needed to freshen up my perspective on my recipe! I was stuck in my smoothie ways and this book has opened up some fun culinary doors for my mornings.
I am not great at planning ahead when it comes to buying groceries or ingredients- therefore I wanted a way to easily search the recipe book for specific ingredients to cobble together a smoothie from what I had on hand, or to target specific ingredients to buy on my next trip to the market!
The idea started to percolate…
Idea
- Scan each recipe in the magazine
- Use Google OCR (optical character recognition) API to scrape the text from each image
- Use python regex interpretation to isolate useful information
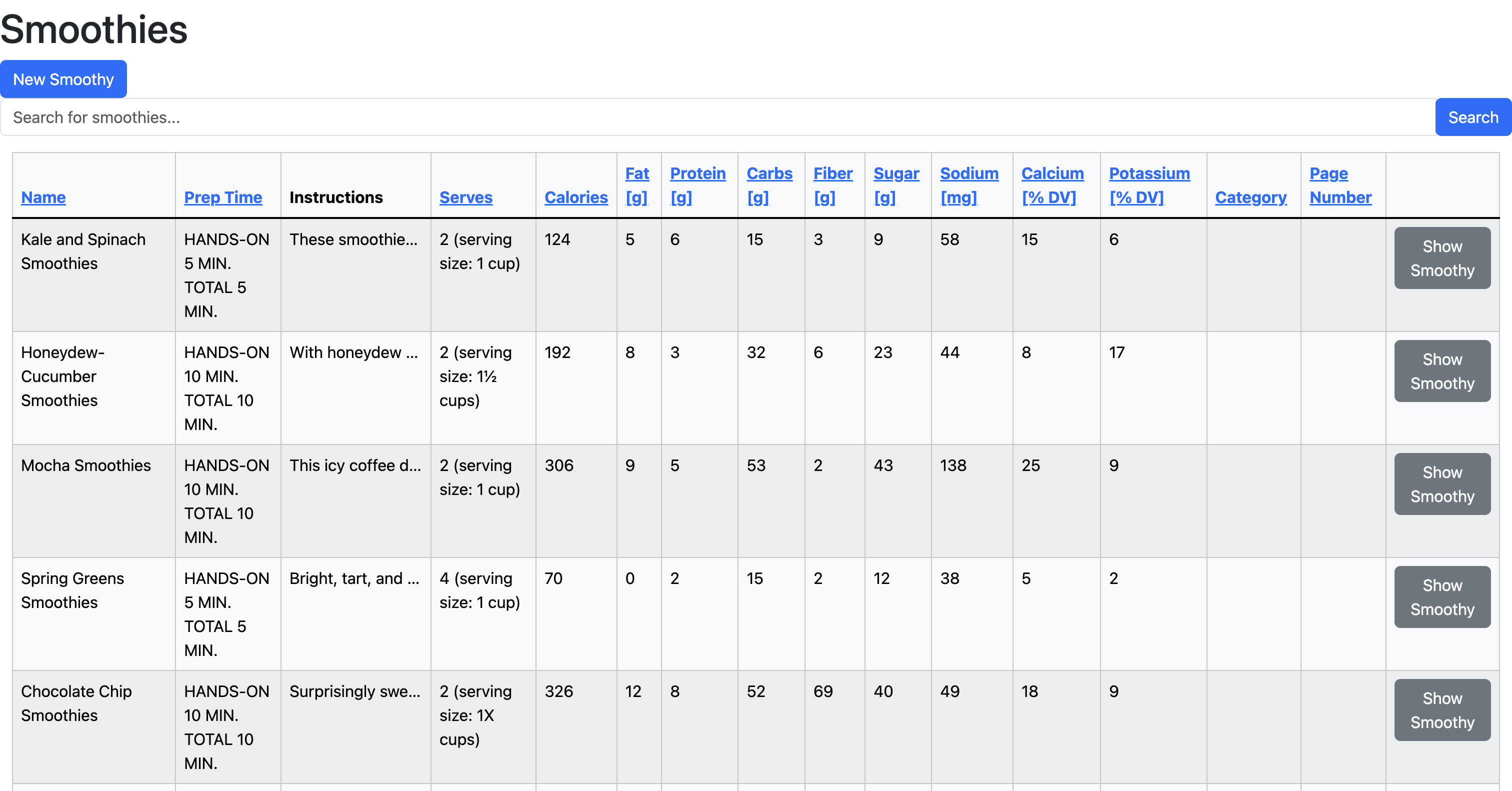
- Create a CRUD searchable database using Ruby Rails and upload each recipe
- Search recipes and edit database at my convenience
Step One
I started by scanning each page of the recipe book, and separating out each recipe into it’s own image (which would help with text parsing):

Google OCR API implementation
Next, (with the help of an ever-present Large Language Model programming companion) I wrote some Python code incorporating Google’s Cloud Vision AI to scrape the text from the images and write all the parsed text (using Regex) to a json file.
from google.cloud import vision
import io
import os
# Google API client initialize
client = vision.ImageAnnotatorClient()
def detect_text_from_image(image_path):
"""Detect text in an image file using Google Cloud Vision API."""
with io.open(image_path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
return texts
Regex Data Isolation
To capture meaningful parameters to add to my database, I needed to split out the information from each recipe which I found relevant (in this case title, the text/ingredients, and the nutritional info):
for file_path in file_paths:
with open(file_path, 'r') as file:
# read content of each text file
content = file.read()
# Find all occurrences of the pattern - anything after "description:" and before "bounding_poly"
pattern = re.compile(r'description:\s*"(.*?)"\s*bounding_poly', re.DOTALL)
matches = pattern.findall(content)
# remove newline chars
matches2 = matches[0].replace('\\n', ' ')
patterns = [re.compile(r'^(.*?)\sHANDS-ON'), re.compile(r'(HANDS-ON.*?TOTAL\s\d+\sMIN.)'),
re.compile(r'SERVES\s(.*?)\sCALORIES'), re.compile(r'CALORIES\s(.*?)\sFAT'),
re.compile(r'FAT\s(.*?)\sPROTEIN'), re.compile(r'PROTEIN\s(.*?)\sCARB'),
re.compile(r'CARB\s(.*?)\sFIBER'), re.compile(r'FIBER\s(.*?)\sSUGARS'),
re.compile(r'SUGARS\s(.*?)\sSODIUM'), re.compile(r'SODIUM\s(.*?)\sCALC'),
re.compile(r'CALC\s(.*?)\sPOTASSIUM'), re.compile(r'POTASSIUM\s(.*?DV)'),
re.compile(r'TOTAL\s+\d+\s+MIN\.\s*(.*?)\s*SERVES')]
Ruby Rails Database
Next, I needed a place to host my database. I chose Ruby Rails because it is super easy to implement. I incorporated Bootstrap to format the table, and I used ransack to filter my database to make it searchable.
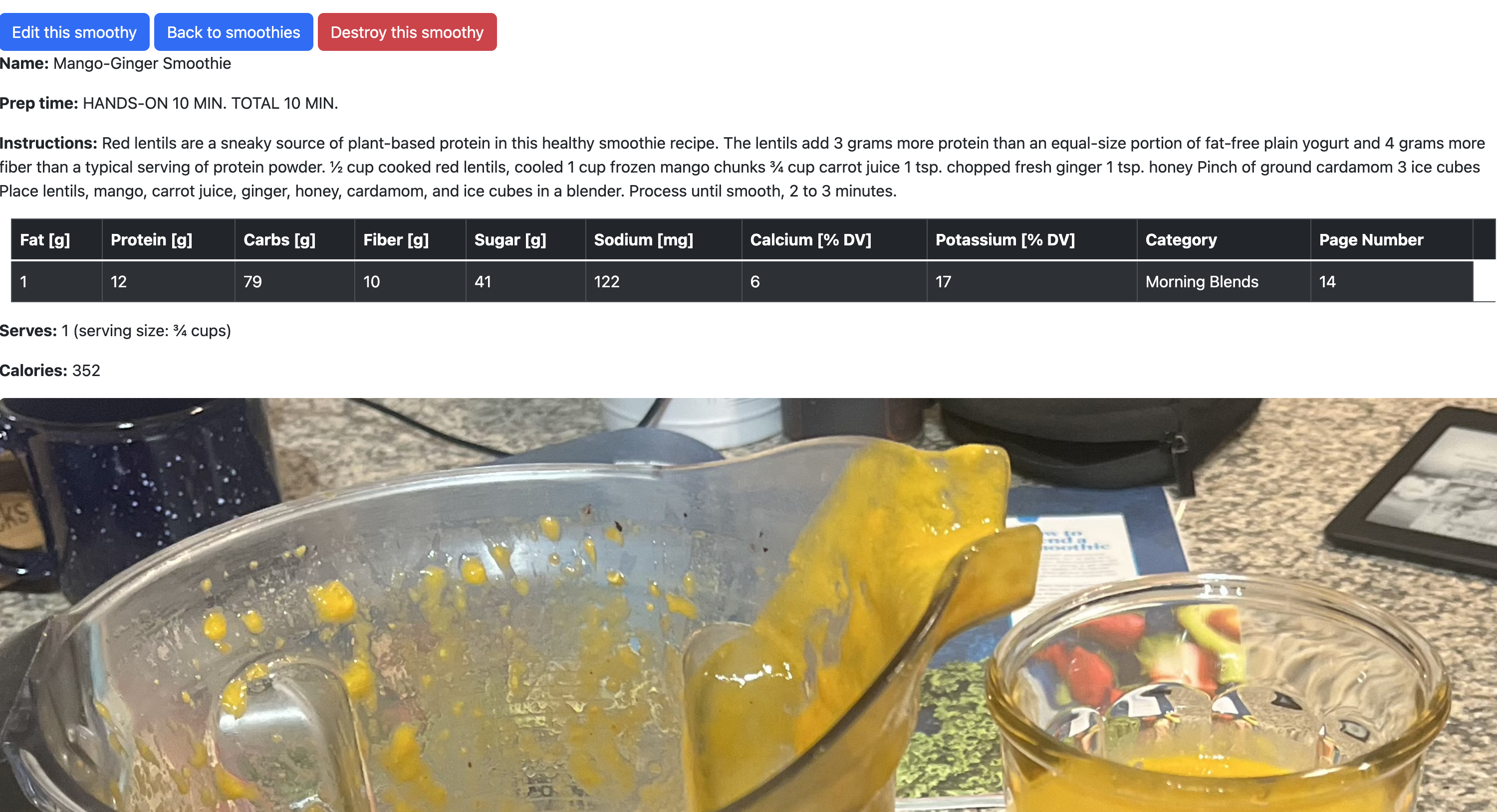
Lastly, I used the active_storage default Gem to create an image upload option, so as I made each smoothie I could include a photo of the end result in the database!
Check out my github for the full code and more details on the project!



